The Wooden Nickel is a collection of roughly a handful of recent topics that have caught our attention. Here you’ll find current, open-ended thoughts. We wish to use this piece as a way to think out loud in public rather than formal proclamations or projections.
1. CPUs vs GPUs
“Use the right tool for the job”
The infrastructure foundation needed for giant generative large-language models (which services like ChatGPT are built on) is very different from how data centers have been constructed and organized in the past. These models, using variables numbering in the tens and hundreds of billions, consume and crunch enormous amounts of data to train a single model over the course of months. This computing power is far more intense and specific than traditional data center computing infrastructure. Whereas the computing resources used to host and execute software that powers databases, emails, Enterprise Resource Planning, and more are suitable for a breadth of workloads and have an established ecosystem using it, it is woefully inefficient for the raw computer power needs of these enormous models.
The heart of a computing unit or networked system for so long has been the trusty CPU (long the dominant domain of Intel and now more recently AMD), but for Artificial Intelligence workloads of the scale of ChatGPT, a different tool is needed for the job: the GPU.
The key difference between these two pieces of hardware is in the way they process calculations. While the computing core in a CPU processes in a sequential manner, a GPU processes data concurrently, or in “parallel”, as most in the semiconductor industry like to say. A CPU will take a task and make all the necessary calculations before moving on to the next task, whereas a GPU takes that same task and divides it up into dozens or hundreds of smaller calculations and recompiles them.
This video helps illustrate the difference.
While a GPU is not suitable or logical for all tasks, it is well suited for jobs that can be simply split into hundreds or thousands of smaller jobs calculated simultaneously because there is no dependency from one job to the other. At the heart of ChatGPT and other large-language models is a network of layers of calculations all built on using linear algebra, a job extremely well aligned to the GPU.
2. CUDA
GPUs were born in the early 1990s out of the need and desire to have special hardware to process graphics, especially the ability to project 3D images onto a 2D plane in a monitor. Images on a screen could be divided up into single or groups of pixels and computed individually before being recompiled into the image on our monitors. Computers would internally pass off graphics responsibility from the CPU to the GPU where computations were done and back to the CPU for final display within an application. GPUs significantly evolved as the dot-com bubble was bursting with the introduction of shaders, a special type of software that made the device programmable. Now, even after manufacturing, engineers could tinker with their hardware to maximize and optimize performance rather than being locked into the commands and abilities pre-manufacturing.
The problem was that shaders are extremely complex and difficult to program with their own language specific to graphics. While they were an incremental improvement in utility, their appeal was limited in scope. That is, until the creation of CUDA, Nvidia’s proprietary software framework.
As the story goes, a Stanford University chemistry professor and researcher began experimenting with using graphics cards designed for computer gaming to do molecular modeling. He converted his modeling inputs into the language of graphics. What took him weeks to do with Stanford’s supercomputer took him a matter of hours with a collection of chips designed for video games. He emailed Nvidia’s founder and CEO, Jensen Huang, to say thank you “for making my life’s work achievable in my lifetime” and in doing so sparked an idea: what if this hardware was made accessible to people with software needs beyond the world of graphics? CUDA was born.
At the time, Nvidia was the market leader in serving the graphics market and was worth several billion dollars when measured in market capitalization. But the revelation of making the GPU more general purpose was too big of an opportunity to ignore. Rather than staying in a niche lane, Huang embarked on a “bet the company” type of endeavor to serve high-performance computing needs. Starting in 2006, Nvidia significantly ramped up investment in its software offerings to build up CUDA as the standard operating system for handling GPUs. While shaders were notoriously difficult to code, CUDA would be built in a manner compatible with the most popular programming languages: C++, Python, and Java. It would abstract away the difficulty of programming shaders with a common interface. As a result, Nvidia created the ingredients for a thriving ecosystem, making software with fewer frictions for millions of programmers and working with them step-by-step to show the connection between software programmability and improved output.

Cuda took six years to develop but it, in essence, gave the power of supercomputers to thousands of researchers around the world. Today, the platform has millions of developers, several times larger than any of their direct competitors with far more resources available to users and for a broader range of disciplines. Applications in chemistry, biology, computational mechanics, fluid dynamics, nuclear energy, medical imaging, and many, many more make use of the Cuda platform to discover drugs, model the weather, scan medical images for diseases, and more.
Nvidia, therefore, has evolved to become a software company that monetizes through the sale of hardware; as management frequently likes to boast, the company employs more software engineers than hardware engineers. While Nvidia is not the only company that designs and makes GPUs, their lead in software scale, breadth, and investment trounces the competition, providing a significant moat.
3. Management
4. Accelerated Innovation
Crediting management as a special advantage to a company can often seem like a catchall, but it’s hard to play revisionist history in the story of Nvidia and end up in the same spot without strong management and leadership. So often investors look for repeatable recipes to compound results over the long run: buy cheap stocks, throw out anything with high Debt/Cap ratios, etc. With good reason: porting over a template of a successful investment in the past to new scenarios can help tilt probabilities in an investor’s favor.
But that framework is a bit less relevant in many technology scenarios as what matters more is about imagining future environments and what will matter going forward. Those revelations often are unfamiliar and incompatible with past analogues. And when someone gets that right, and gets it right in a big way, you have to respect the unique, idiosyncratic, and inimitable qualities that go into how we got to where we are today; great managers with a unique vision that can execute on that vision are not a dime a dozen. But the fact of the matter is that Nvidia has foreseen and caught shifts in technology use cases multiple times now; once is an occurrence, twice is a coincidence, but three times is a pattern. And Nvidia has shifted and invested ahead of major trends (and competitors) years in advance.
First, they moved from graphics to accelerated computing by devoting major R&D dollars and time to serving the high-performance computing markets in the mid-2000s with CUDA. Management was heavily criticized and charged with potentially surrendering the graphics market to their competitors (AMD namely) and wasting what would be billions of dollars and years of time to develop something unproven.
Second, investments in their software libraries and ecosystem helped usher along deep learning and neural network formation when it was more in its infancy. Through Nvidia’s internally developed assets, the technology and techniques common to supercomputers and major research labs made their way into recommendation-type models along with image recognition and classification systems. These were the seeds of deep learning systems that dozens and hundreds of companies would build on and they all built on Nvidia’s hardware and software. But no one invested with the boldness that Nvidia did. Remember, it was only a year ago that ChatGPT entered the public consciousness. Dreams of autonomous computing agents, robotics, and autonomous vehicles were far further away both in reality and in dreams in this 15+ year span where the company and its management are investing. But those dreams wouldn’t be in anyone’s imagination if it wasn’t for the revolution that Nvidia sparked upon global data centers.
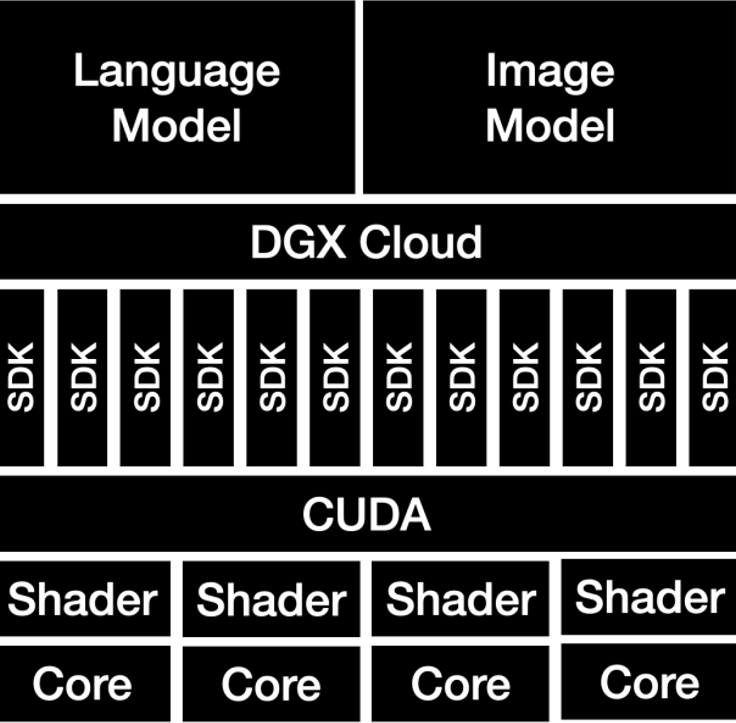
Their chips and software found new use cases and brought new levels of computing power just as cloud computing started to take root. Simultaneously, CEO Huang was one of the earliest and foremost counselors that Moore’s Law was dying in its original permutation and new methods of computing would be needed. Not only would special purpose hardware be needed for respective tasks but new architectures and ways of thinking about how data centers are constructed and organized would need to be undertaken. Whereas for so long the basic unit of computing had been a single device like a PC or a server, going forward the entire data center would need to be thought of and optimized as if it were a singular unit of computing. This required a rethinking of how storage, computing units (whether CPUs, GPUs, or other processors), and networking infrastructure were compiled. Specifically, to tackle the biggest and most resource-intensive tasks in the future, each piece of the data center needed to be optimized to work in harmony with each other to maximize throughput and to accentuate the parallel nature of accelerated computing. Nvidia saw this need long before others building up proprietary technology to link GPUs together, racks of GPU servers to each other with unique networking assets, new CPUs to feed instruction to GPUs, and subsidizing the entire supply chain to bring the whole ecosystem with it and enable it all. It has amounted to a three-headed hydra with one competitive advantage built upon another: GPU hardware, CUDA and other software, and networking technology to scale up servers together as a singular unit.
Today, the landscape for AI chips looks vastly different than it did just a handful of years ago. Direct competitors like AMD have made progress on some very real and creative innovations to stand out. Customers like Microsoft are designing their own chips specifically built for AI acceleration in-house. Google has an excellent ecosystem around its own internal chips and is very rapidly growing in scale. The open-source software ecosystem continues to grow and develop to nip at the software moat. All of these efforts though are no guarantee to catch up to a decade-plus lead that Nvidia has built; even an optimistic scenario would put AMD and Intel, combined, at less than 5% of the total market in 2024. And that’s before we get to the fact that Nvidia has accelerated its innovation timeline from 2 years to 1, just as competitors will ramp their products in any meaningful volume.
Nevertheless, Nvidia, just as it did before, is moving its investments further up the value chain, expanding the reach, utility, and appeal of its software assets and thus its chips. Industry-specific modeling software and tools are available on top of CUDA. Nvidia’s own supercomputers are being collocated along with the major cloud providers to expand reach. Nvidia is bringing its own AI models and parameters that customers can use out of the box or tweak for their own use cases. Just like in the mid-2000s when researchers had more use cases for scientific computing because of the availability of CUDA and consumer graphics chips, Nvidia is betting that the proliferating desire to incorporate generative AI is a new avenue to bring people into their software stack and hardware infrastructure.
Rarely due companies see ahead of multiple shifts within the technology space; the landscape is just so hard to figure out and competition is real. Further, it would be simple and human for the company to sit on its advantages multiple times and reap the rewards of past labors rather than dig in for the next challenge. But to realize unique results you must do unique things and the consistent pattern of building upon past strengths and accelerating innovation rather than resting is something that you don’t see that often.